Mangari
Kotlin 361 commits Last commit on Sep 15th, 2024
Prelude
January 13th, 2024 was the day the Tachiyomi project ended. Tachiyomi was an open-source Android application for downloading and reading manga, webtoons, and comics. The base project only supported the reading experience alongside support for extensions to download content. The extension implementations were a separate community driven project and largely were the primary way that users downloaded their content to be viewed within Tachiyomi. When the projects were paired together it was a seamless experience.
What now?
In the aftermath of Tachiyomi ending I (along with most of the community) looked for alternatives. Quite a few forks of the base project and extensions popped up but without the community coming together to support them in a unified manor, it was doubtful if they would succeed. After auditing all options I assessed that the base Tachiyomi project itself is relatively stable and doesn't need to be changed that often; the bigger problem is the extensions.
Extensions for Tachiyomi provide a source for searching and downloading content from a specific site. Traditionally this is done by either scraping the website and downloading the content or by accessing the content via a dedicated api exposed by the site. This abstraction allows the user to choose what to download and where from.
Option 1: Supporting the existing implementation
In the past I had built my own extension for a web comic I was reading, so I am accustomed to the overall structure of an extension. Looking at the code for a couple sites I normally download from though showcased a wide array of different kinds of implementations. It would be difficult to long term support this by myself, even if I dropped the sites I don't need. This would also inherit a pain point encountered from time to time: extensions breaking due to website or Cloudflare changes. When this happens you are unable to read any content not downloaded. This encourages users to download a bunch of content at once, increasing the load on the sites.
Option 2: Writing my own
Taking a step back from the existing implementation I looked at the problem as a whole. Scraping websites and extracting content is a solved problem. At the scale that Tachiyomi was doing it effectively it was crushing the sites like a distributed attack constantly. It doesn't need to be this way for my own project because I don't plan on distributing it at all. We could in theory just have a web service occasionally poll the sites and only download what we need. The service becomes the source of truth and even if my scraping code breaks, I have access to the backlog of content. Even if the latest is unavailable until I fix the broken scraper. The initial sync will be intensive, but compared to Tachiyomi it will be nothing.
This sounded promising so I investigated how I could integrate this theoretical web scraping service into an extension. Although I could write this myself, along with extracting data from the soon-to-be downloaded files: this is also a solved problem. I came across a project called Komga, it not only can serve locally hosted content but also happens to already have a Tachiyomi extension. This in theory could solve the other half of the problem for me. The only major risk in relying upon this project is if they drop support for their extension long term, but that is a problem for future me who loves taking on those kinds of surprise challenges.
Mangari
Ultimately I decided upon Option 2, the service soon to be named Mangari. Realistically it wasn't that simple though. I did review a few existing tools that could do different parts of the job, but the closest I could find was one called mangal. This tool could do all the web scraping, but was all configured in Lua. I was not comfortable jumping into that codebase with minimal experience in web scraping and Lua, which I have not touched since the PSP was king.
Web scraping
Previously with projects like Progress and Busted I have leveraged the Spring framework in Java or Kotlin for spinning up web services. This would allow me to easily write tests and utilize patterns I have used for years. This would also allow me to utilize my JSoup experience from Tweedle, but realistically I have not touched that in years. In the end I threw out all of that sane decision making and wrote it in Python with BeautifulSoup as the core.
Cloudflare
One of the biggest challenges in web scraping is trying to bypass Cloudflare protections. They are typically in place to deter bots and denial of service attacks. This adds an extra layer of security to any website (for a price) to ensure malicious actors are not misusing your website.
FlareSolverr acts as a proxy that can attempt to bypass all of those protections. It is updated semi-regularly and has a large community of users using it to enable their web scrapers. This is used to scrap all sorts of websites and is supported by many tools as a built in option if you self host it. It isn't perfect, but it is better than just switching your headers and hoping for the best like with Tachiyomi.
Komga
The last piece of the puzzle was understanding how the data should be formatted on disk. After reviewing all of the documentation I could find and testing out a few options I ended up on the following format:
Library/Series/cover.jpg
Library/Series/mangari.json
Library/Series/series.json
Library/Series/Chapter 1.cbz
/0.jpg
/...
/190.jpg
/ComicInfo.xml
Library/Series/...
Library/Series/Chapter 203.cbz
The library and series paths are pretty self explanatory. Stepping into the series folder we want to be able to display a cover image for the whole series, along with metadata and the chapters themselves. The structure of mangari.json is custom and provides the information I need about the source site, how often we should refresh, and when we last refreshed. The series.json file is a standard metadata format from mylar.
Looking at the cbz file, it is a standard comic book zip archive format. The variant used here includes the images along with a ComicInfo.xml file per chapter. A now defunct comic book downloader named ComicRack pioneered this format and was so popular that it now lives on beyond the downloader with community driven support.
With all of this figured out I formatted the files carefully within the correct directories, and would leverage Komga's api to refresh the metadata on their side. This updates the index and within no time I am able to see the latest content within Tachiyomi.
Android
With all of the pieces coming together, I wanted to be able to be able to check the status of things without directly checking the docker output logs. Taking my time I went through options like Flutter and .NET but ultimately came back to my roots and wrote it in Android via Compose. Using a simple api I was able to display the currently monitored series, update the refresh interval, and manually trigger a refresh. Eventually this would become more feature rich, but that took a long time to backfill.
Final thoughts
This project has been a blast to write. Building out systems like this is really fun and allows me to stretch myself out into areas I previously took for granted. Even in writing this all out I see now where I can improve in the future to make better decisions moving forward. If only I could fix that one pesky website failing Flaresolverr randomly...
Mangari v2
I was a bit optimistic and vague earlier when describing how I would work around Cloudflare. Flaresolverr ended up not being as stable as I wanted. Some websites had some pretty tough anti-bot code to work through. Lastly, using things like Python's requests library out of the box will never be robust enough for sites that know you are going to scrap them. It just isn't good enough to get through fingerprint checks.
Web traffic fingerprint queue
After six months of dealing with Flaresolverr breaking randomly and following the various issue trackers, I wanted to see if I could work around them sometimes just not being reliable. I would prefer that the service would run autonomously and I wouldn't need to constantly keep an eye on it like a pet. Wouldn't it be nice if I could just manually click the box and bypass captcha if it was broken like a mechanical turk?
In theory if I could refactor the implementation so that I no longer directly rely upon things like Flaresolverr, I could swap it out with other options. It could be one of the many forks of Flaresolverr, or something wild like an Android application that directly loads the content into a WebView and pipes the content back like a proxy. This would allow me to experiment with different options without needing to rewrite my whole codebase.
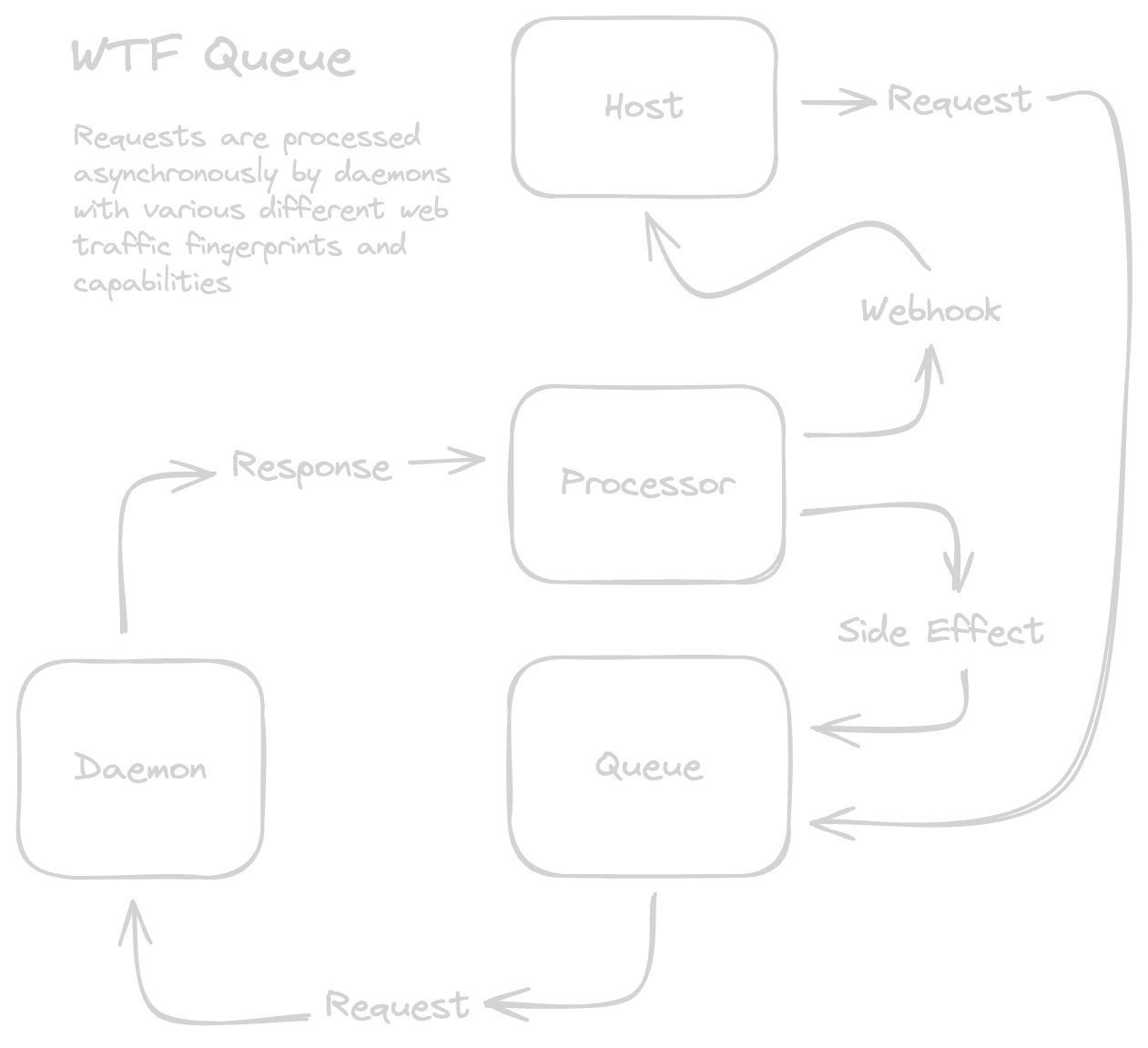
Rewriting the whole codebase
Although my first pass at this was written in Python, I didn't think adding this kind of abstraction would be the best idea on that codebase. I am far more comfortable with Kotlin and frankly the fact that Python uses blank lines as function and class definitions was driving me mad.
I wrote out my initial draft of the queue implementation, and got to work recreating my web scraper in Kotlin using Ktor and JSoup. Getting the existing api contract up and running using Ktor was really simple, even though it was my first time using the framework. I have used JSoup before, but not with the level of detail needed for this project. In the end, css queries were the MVP and serve as the backbone of the project.
I ended up writing three different Daemon (request handler) implementations. The first one was for Flaresolverr, the second was for MITM proxy, and lastly an Android client for proxying manually if things ever broke. I have some other options as well that I might try, a browser plugin could be nice for example. The idea around this framework is I should be able to adapt it to pretty much any tool if needed to ensure it keeps on working as intended.
Final thoughts
So far this latest iteration of Mangari is stable and from my perspective maintainable. Time will tell if that holds true. I'll learn eventually if some of my gambles with things like Komga were worth it. Worst case I can always write my own extension, but that is a problem for future me.